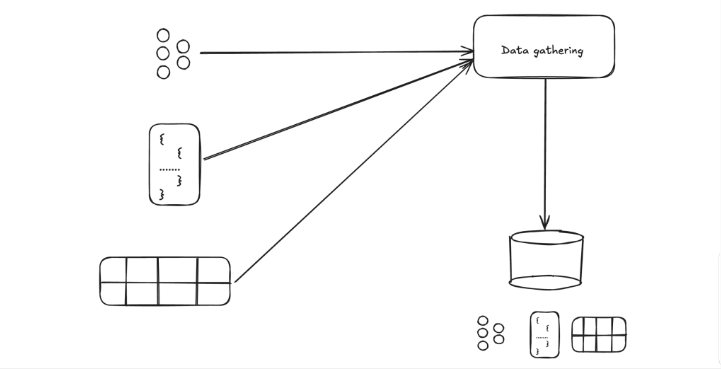
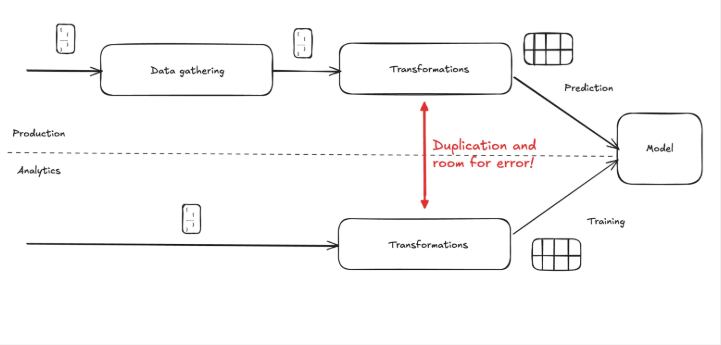
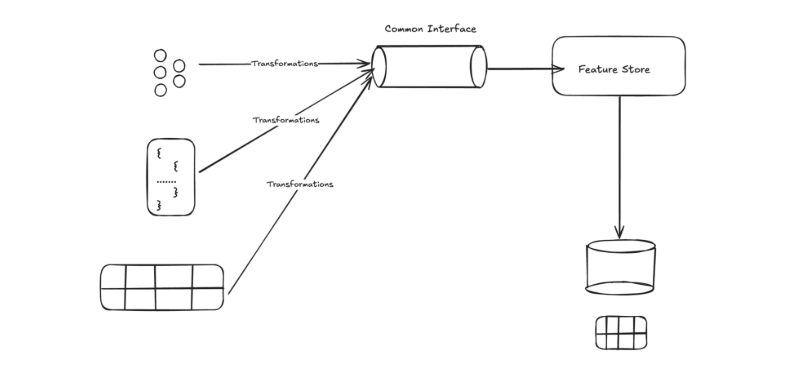
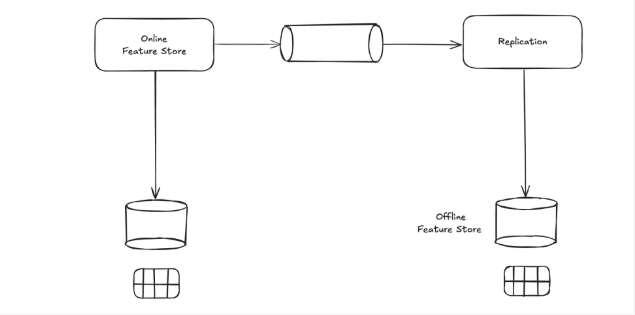
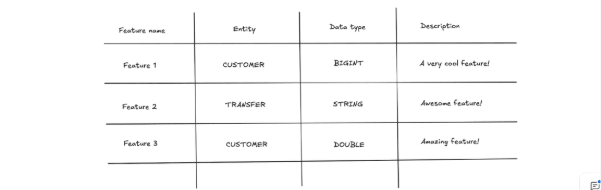
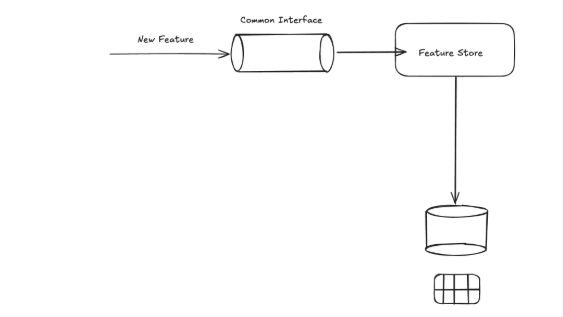
That helps, but it doesn’t automatically solve point-in-time correctness, discoverability, and repeatability of training sets—especially when the data comes from many systems.



Teaser
People profileContent Type
BlogPublish date
03/02/2026
Summary
"When you join, you’ll see your own growth mirrored by the growth of the company. You won't just be watching change happen; you’ll be a direct part of it." Ataro Shoji (He/Him) Payment


Teaser
People profileContent Type
BlogPublish date
06/27/2025
Summary
We sat down with SK Saraogi, Head of Expansion APAC, to discuss our strategic expansion into Hyderabad, India 🇮🇳Read more to discover why Hyderabad is the perfect location for our second glo

Teaser
People profileContent Type
BlogPublish date
06/06/2025
Summary
Driven by a passion for growth and team development, discover how Anna Pavlics advanced from Agent to Team Lead in Wise's Fraud Prevention team 🚀 "We put tremendous effort into bui

Teaser
People profileContent Type
BlogPublish date
02/18/2025
Summary
Head of Servicing Scale and Experience, Ian Rynne, discusses his journey from starting as a Customer Support agent to becoming the Head of Servicing Scale and Experience at Wise.
+(1).png)
Teaser
Our cultureContent Type
BlogPublish date
05/15/2024
Summary
My name is Cynthia. I'm a fraud agent at Wise, based in the Austin office. We strive to prevent fraudulent activity on the Wise platform. It can be tricky, as Wise supports many diff
+(1).jpg)
Content Type
BlogPublish date
01/24/2024
Summary
Wise’s volunteer day is not just a perk; it’s a celebration of community, camaraderie, and making a difference.Meet Claire Adelman, Customer Support Training Specialist, and Javier Perdo
.jpg)
Teaser
People profileContent Type
BlogPublish date
11/24/2022
Summary
Hi! My name is Delis and I’m a Due Diligence Agent (CDD) in our Tallinn team, focusing on business verification. What this means is that I onboard high risk businesses by assessing their r
.jpg)
Teaser
People profileContent Type
BlogPublish date
11/24/2022
Summary
Hi! My name is Rza Mustafayev and I’m a Due Diligence Agent in our Latin America & Middle-East and Africa Region, focusing on personal and business customers. What this means is that I:Rev